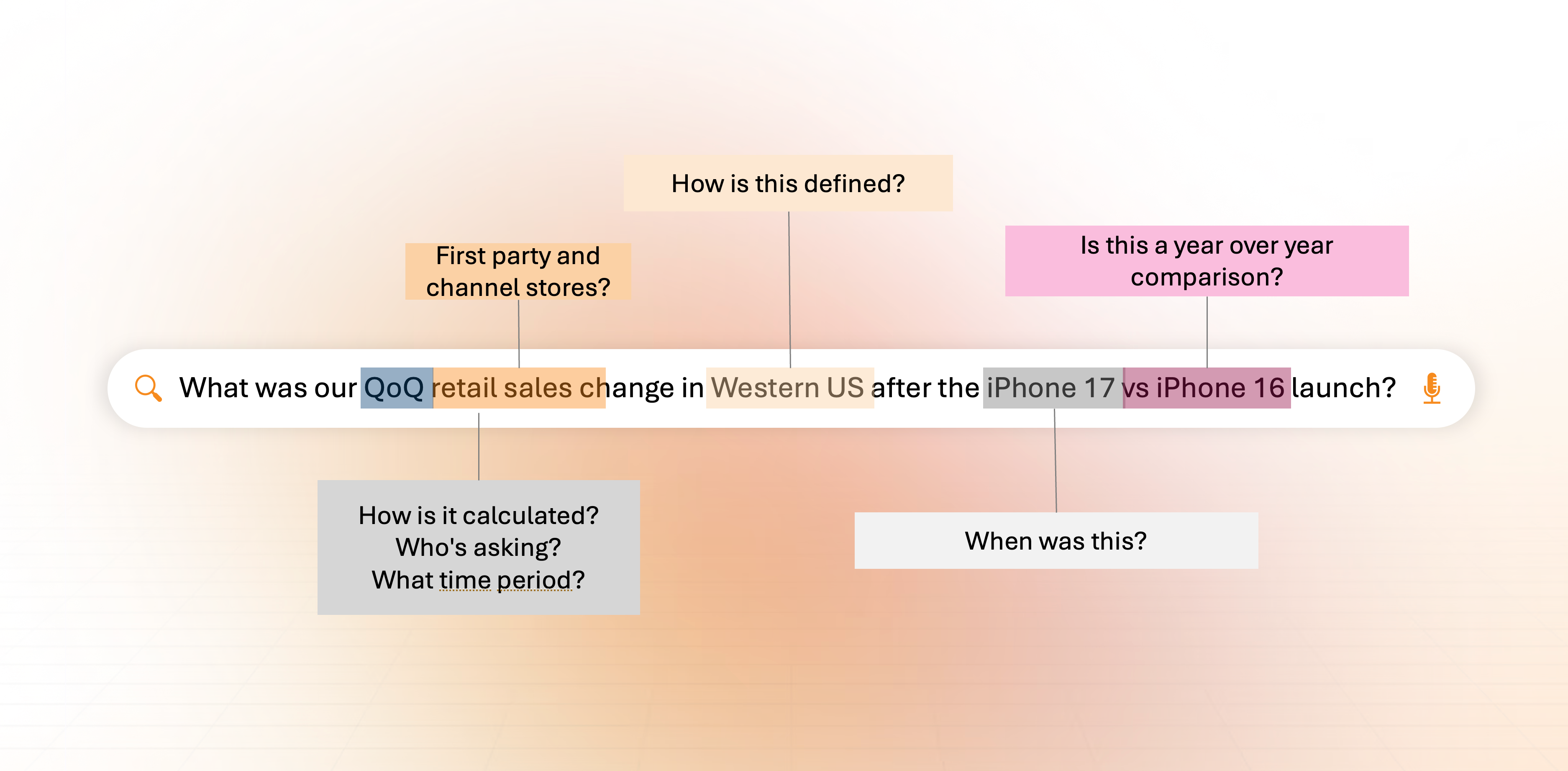
The Context Layer: Why Answering a "Simple" Business Question Is So Hard for LLMs

Knowledge graphs are gaining increased attention as critical enablers for large organizations to apply generative AI successfully. Gartner recognizes (Gartner 2024 Hype Cycle for Artificial Intelligence), that knowledge graphs are entering the “Slope of Enlightenment” phase.
As more organizations launch projects, this powerful data technology will enable smarter, more contextually aware systems that drive innovation and efficiency across industries.
Benefits of utilizing knowledge graphs include:
App Orchid’s Platform utilizes knowledge graphs extensively to help organizations get unified data access, rapidly scale AI use cases, and extract insights in record time.

The traditional method of data storage is through relational databases, where data is stored in interconnected tables. Relational databases are ideal for use cases where data models are static and business processes are stable. This means:
Relational databases are ideal for structured, well-defined datasets, while knowledge graphs are better suited for complex, interconnected, and often more loosely structured information.
A knowledge graph excels at unifying data across disparate data sources, creating connections between previously isolated datasets, and making this unified data accessible and understandable across an organization. This allows for a comprehensive view of the data across the organization.
Traditional tools only present information from a specific department or system, without showing its relationship to other data. This can cause delays in data accessibility, as data needs to be manually pulled or transformed before it can be shared across departments.
For example - Customer data can come from multiple systems such as :
A knowledge graph acts like a unifying data model, accessing data in different systems seamlessly, allowing you to unlock cross-functional use cases. In addition, knowledge graph provides real-time access to integrated data across different silos, ensuring that stakeholders can access the latest information when needed. This is especially valuable for decision-making and analysis. In this example, you can use this combined dataset to:

Traditionally, enterprise data is managed using multiple schemas and data models. As a consequence, different departments interpret terms differently. Additionally, as reliance on external data grows, it's not feasible to enforce a universal definition across all data. This results in multiple datasets and silos within each group.
A knowledge graph acts as a central repository that is accessible to all departments, enabling teams to access and explore interconnected data. It provides a common language and understanding for the entire organization, making it easier to collaborate on data-driven projects. Depending on access, role, and other factors, each team, organization, or application has a relevant subset of the graph, enabling them to access data in an organized and streamlined way.
Here’s an example of how a body of data in the medical field can be used by different teams based on their focus.

Graphs can be classified as: (1) virtualized, where the graph stores pointers to data stored elsewhere, or (2) materialized, where the data is stored directly on the graph.
A virtualized knowledge graph can also be called “ontology-based data access”. By virtualizing the data, knowledge graphs avoid the need to physically copy or move data, preserving original schemas and metadata. This allows for seamless integration of new data sources and systems without disrupting existing analytics and reporting.
The App Orchid platform creates an ontology that represents the underlying data. When an application or analytics requires data, we query the underlying systems for just the data required by the ontology and create a graph. This graph is used to answer questions, build analytics, and generate insights. This helps you seamlessly access data without the need to copy your data, reducing cloud costs and improving performance.
Traditional data integration methods often struggle to scale when new data sources are introduced, further entrenching silos.
There’s always new data and systems being added to your enterprise. This may require the re-engineering of data warehouses, analytics and apps. With enterprise knowledge graph (EKGs), you can:
Knowledge graphs play the role of a semantic layer. In enterprise data management, a semantic layer is an abstraction layer that sits between raw data sources and end-users, providing a user-friendly way to interact with complex datasets without knowing the technicalities of the underlying systems.
A knowledge graph goes beyond by capturing relationships - structuring and organizing data in a way that makes it more accessible, understandable, and usable by both humans and machines. This semantic layer helps translate database data into structured, meaningful information that can be easily queried, analyzed, and used for decision-making. In other words, the graph provides a layer of intelligence on top of the enterprise landscape, making it easier to work with by defining the relationships between different data sets in a way that aligns with business concepts or real-world entities.
Knowledge graphs and ontologies are being adopted to provide a semantic layer for enterprise applications since they can store both data and relationships. LLMs can understand knowledge graph content better than table headers in a database.
Knowledge graphs provide a flexible, adaptable, and future-proof solution for organizing and curating enterprise data, enabling data reusability, and facilitating seamless integration of new data sources and systems. We are extremely bullish on knowledge graphs being the engine that powers the next wave of insights and actions for enterprise organizations.


Experience a future where data and employees interact seamlessly, with App Orchid.

.jpg)